回顾一下FedAvg算法流程:
- 每一轮迭代开始前,server随机选取部分clients - $max(C·K,1)$ ,将当前的全局模型参数分发给选中的客户端
- client做参数初始化,在本地执行$E$个epoch的更新后,将更新后的参数上传给server,即下图的ClientUpdate算法
- server按照下图红色框的方法计算参数的加权平均并更新
- 重复步骤1-3
FedAvg算法在服务端和客户端传递的是整个模型的参数(梯度),当模型规模较大时传递的参数也会很多,通信成本也会激增。

FedMD
思路
-
Communication at a high level——simplest approach: model distillation
-
Key components: model distillation and transfer learning(引入公共数据集)
算法流程
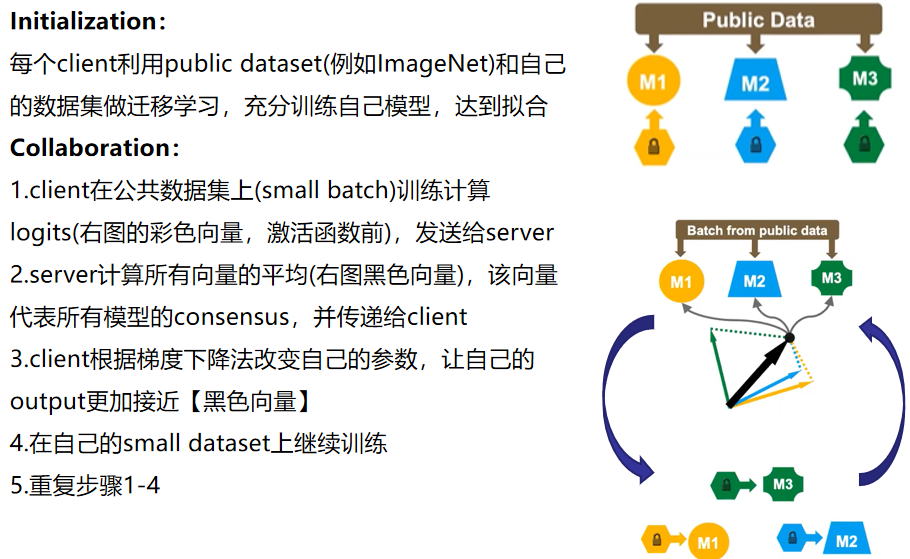
We re-purpose the public dataset $D_0$ as the basis of communication between models, which is realized using knowledge distillation. Each learner $f_k$ expresses its knowledge by sharing the class scores, $f_k(x_i^0)$, computed on the public dataset $D_0$. The central server collects these class scores and computes an average $\widetilde{f}(x_i^0)$. Each party then trains $f_k$ to approach the consensus $\widetilde{f}(x_i^0)$. In this way, the knowledge of one participant can be understood by others without explicitly sharing its private data or model architecture. Using the entire large public dataset can cause a large communication burden. In practice, the server may randomly select a much smaller subset $d_j⊂D_0$ at each round as the basis of communication. In this way, the cost is under control and does not scale with the complexity of participating models.
实验结果
论文做了两组实验(均考虑了iid 和 Non-iid情况)
- Hand written digits and character
- Public datasets = MNIST(手写数字)
- Private datasets = subset of FEMNIST(手写字母)
- Colored images of pets and objects
- Public datasets = CIFAR10
- Private datasets = subset of CIFAR100
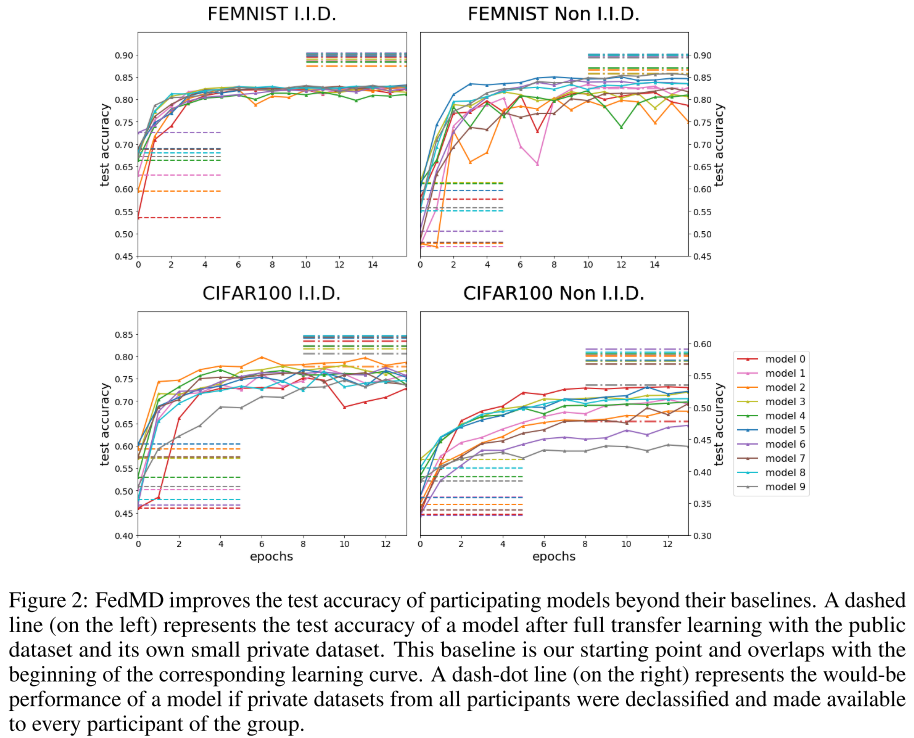
client采用的是2-4层的CNN,使用不同的通道数和dropout。图中的折线表示FedMD算法每个client在测试集上的准确率。左下方的虚线是指不使用联邦学习(在transfer learning之后 collaboration之前)的performance,client只在自己的私有数据以及公有数据集上训练的结果,这是baseline。右上角的虚线表示每个client拥有全部的数据所能达到的实验结果。
结果表示,FedMD算法达到了比baseline更好的性能,但是没法达到最优结果。
First they are trained on the public dataset until convergence, — these models typically have test accuracy around 99% on MNIST and 76% on CIFAR10. Secondly each participant trains its model on its own small private dataset. After these steps, they go through the collaborative training phase, during which the models acquire strong and fast improvements across the board, and quickly outperform the baseline of transfer learning.