Multimodal Machine Learning: A Survey and Taxonomy阅读笔记
旨在通过机器学习的方法实现处理和理解多源模态信息的能力。目前比较热门的研究方向是图像、视频、音频、语义之间的多模态学习
多模态可以划分为以下五个研究方向:
- 多模态表示学习 Multimodal Representation:学习如何利用多种模态的互补性(complementarity)和冗余性(redundancy)来表示(represent)和总结(summarize)多模态数据。多模态数据的异质性(heterogeneity)使得构造这样的表示形式具有挑战性,比如文字是符号(symbolic),而音频和图像是信号(signals)
- 模态转化 Translation:将数据从一种模态转换(映射)到另一种模态,不仅数据是异构的,而且模式之间的关系通常是开放式(open-ended)的或主观的(subjective)的,比如说,存在许多描述图像的正确方法,并且可能不存在一种完美的翻译。
- 对齐 Alignment:从两个或更多不同的模态中识别元素之间的直接关系。比如说,我们希望将食谱中的步骤与正在制作菜肴的视频对齐。我们可能需要测量不同模态之间的相似性,并应对可能的长期依赖性(long-range dependencies)和歧义性(ambiguities)
- 多模态融合 MultiModal Fusion:来自两个或多个模态的信息结合起来进行预测。比如说,对于视听语音识别,将嘴唇运动的视觉描述与语音信号融合在一起预测口语单词。来自不同模态的信息可能有不同的预测能力和噪声拓扑,其中至少有一种模态可能会丢失数据。
- 协同学习 Co-Learning:在模态、表示形式和预测模型之间转移知识(transfer knowledge),这可以通过共同训练(co-training)、概念基础(conceptual grounding)和零次学习(zero-shot learning)的算法来举例说明。
详细介绍以上五个研究方向:
多模态表示学习:
单模态的表示学习负责将信息表示为计算机可以处理的数值向量或者进一步抽象为更高层的特征向量,而多模态表示学习是指通过利用多模态之间的互补性,剔除模态间的冗余性,从而学习到更好的特征表示,主要包括两大研究方向:
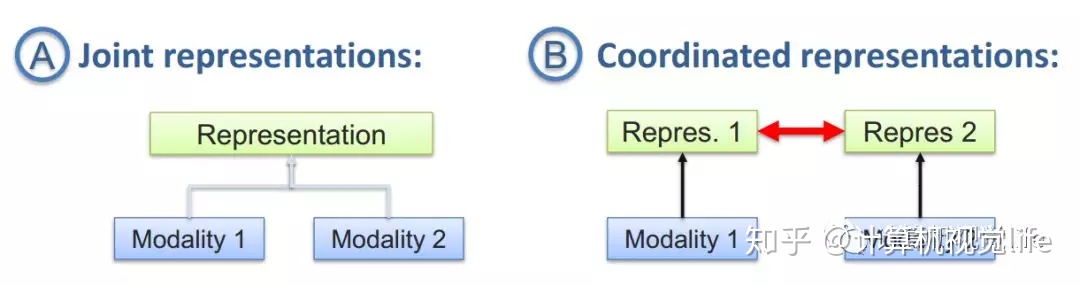
联合表示(joint representations):将多个模态的信息一起映射到一个统一的多模态向量空间
协同表示(coordinated representations):负责将多模态中的每个模态分别映射到各自的表示空间,但映射后的向量之间满足一定的相关性约束(例如线性相关)
利用多模态表示学习到的特征可以用来做信息检索,也可以用于分类/回归任务。
转化Translation / 映射Mapping
常见应用包括:
1.机器翻译(Machine Translation):将输入的语言(即时)翻译为另一种语言,类似的还有唇读(Lip Reading)和语音翻译(Speech Translation),分别将唇部视觉和语音信息转换为文本信息。
图片描述(Image captioning)或者视频描述(Video captioning):对给定的图片/视频形成一段文字描述,以表达图片/视频的内容
语音合成(Speech Synthesis):根据输入的文本信息,自动合成一段语音信号。
模态间的转换主要有两个难点,一个是open-ended,即未知结束位,例如实时翻译中,在还未得到句尾的情况下,必须实时的对句子进行翻译;另一个是subjected,即主观评判性,目标函数的确定是非常主观的。
对齐Alignment
多模态的对齐负责对来自同一个实例的不同模态信息的子分支/元素寻找对应关系。这个对应关系可以是时间维度的,比如电影画面-语音-字幕的对齐;也可以是空间维度,比如图片语义分割(Image Semantic Segmentation):尝试将图片的每个像素对应到某一种类型标签,实现视觉-词汇对齐。
同样,我们将多模态对齐比对分为两种类型:隐式 implicit 和显式 explicit 。
-
显式对齐:
- 主要建模目标是来自两个或更多模态的实例子组件之间的对齐。例如,将配方步骤与相应的教学视频对齐。
- 显式对齐的一个非常重要的部分是相似性度量。 大多数方法都依赖于以不同的方式测量子组件之间的相似性,并将其作为基本的构建模块。 这些相似性可以手动定义或从数据中学习。
- 可分为无监督 unsupervised 和有监督 supervised 。
-
隐式对齐:
- 被用作另一个任务的中间(通常是潜在的)步骤。这样可以在许多任务中实现更好的性能,包括语音识别,机器翻译,媒体描述和视觉问题解答。例如,基于文本描述的图像检索可以包括单词和图像区域之间的对齐步骤。
- 这样的模型不会显式对齐数据,也不依赖监督的对齐示例,而是学习如何在模型训练期间潜在地对齐数据。
- 可分为图模型 Graphical models 和神经网络方法 Neural networks 。
Explicit Alignment
我们将显示对齐分为两种算法:无监督 unsupervised 和有监督 supervised 。
- 无监督方法:
- 适用范围:视频和文本、视频和音频。
- 来自不同模态的实例之间没有直接对齐标签。
- 大多数方法是从早期关于统计机器翻译和基因组序列的对齐工作中获得灵感的。 为了使任务更容易,这些方法在对齐时采取了某些约束,例如序列的时间顺序或模态之间的相似性度量。
- 动态时间规整 Dynamic time warping (DTW)是一种动态编程方法,已广泛用于对齐多视图时间序列。
- 多种图模型 graphical models 也已经以无监督的方式流行于多模态序列对齐工作中。
- 用于对齐的DTW和图模型方法都在对齐上作了限制,例如时间一致性,时间上没有大的跳跃以及单调性。
- 有监督方法:
- 适用范围:视频和文本、图像和文本。
- 来自不同模态的实例之间有直接对齐标签,可能比较弱。对齐标签用来训练相似性度量。
- 许多有监督的序列对齐技术都是从无监督的技术中汲取灵感的。
Implicit Alignment
我们将因式对齐分为两种算法:图模型 Graphical models 和神经网络方法 Neural networks 。
- 图模型:
- 适用范围:音频和文本、文本和文本。
- 这是一些早期的工作,需要手动构建模态之间的映射,比较麻烦。
- 神经网络:
- 适用范围:图像和文本、视频和文本。
- 这是比较流行的工作。
- 比如翻译任务,如果将对齐作为潜在的中间步骤执行,则通常可以改进此任务。 如前所述,神经网络是解决翻译任务的常用方法,一般使用编码器-解码器模型或通过跨模态检索来解决。在不进行隐式对齐的情况下执行翻译时,最终会给编码器模块增加很多负担。
- 解决这一问题的一种非常流行的方法是通过注意力,它可以使解码器专注于源实例的子组件。注意力模块将告诉解码器更多地关注待翻译源的目标子组件——图像区域、句子的单词、音频序列的片段、视频中的帧和区域,甚至是指令的一部分。例如,在图像字幕任务中,不使用CNN编码整个图像,而是使用注意机制让解码器在生成的连续单词中专注于图像的特定部。 学习注意力集中在图像的哪一部分上的注意力模块通常是浅层神经网络,并且与目标任务一起被端到端地训练。
- 注意模型也已经成功地应用于QA任务,因为它们允许将问题中的单词与信息源的子组件对齐,例如文本、图像或视频序列。这样可以提高准确性,并导致更好的模型可解释性。
- 已经提出了不同类型的注意力模型来解决该问题,包括分层、堆叠和情景记忆注意力 episodic memory attention。
多模态融合 MultiModal Fusion
多模态融合负责联合多个模态的信息,进行目标预测(分类或者回归),属于MMML最早的研究方向,按照融合的层次,可以将多模态融合分为pixel level、feature level 和 decision level三类,分别对原始数据、对抽象的特征和对决策结果进行融合,而feature level又可以分为early和late两个大类,代表了融合发生在特征抽取的早期和晚期,还有将多种融合层次混合的hybrid方法。
协同学习 Co-learning
协同学习是指使用一个资源丰富的模态信息来辅助另一个资源相对贫瘠的模态进行学习。
比如迁移学习(Transfer Learning)就是属于这个范畴,绝大多数迈入深度学习的初学者尝试做的一项工作就是将 ImageNet 数据集上学习到的权重,在自己的目标数据集上进行微调。